Strumenti e metodologie di programmazione

Questo è il post #11 di 12 nella serie “Fondamenti di Programmazione 101”
Produrre software richiede molto più che semplicemente scrivere codice. Il processo richiede molti più steps come per esempio, pianificare il codice che dobbiamo scrivere, scriverlo, integrare il codice scritto con codice preesistente, condividerlo con altri sviluppatori, testare il codice che abbiamo scritto, deployare il nostro codice in modo che possa essere usato da altri utenti, aggiungere nuove funzionalità e risolvere eventuali bugs ed errori che possono verificarsi una volta che il codice è stato deployato.
Concetti sui sistemi di versionamento del codice
Un sistema di versionamento del software (Version Control System) viene utilizzato per gestire le modifiche in
documenti, programmi software e altri tipi di files.
Sono utilizzati dai programmatori per gestire diverse versioni del software e tracciare tutti i cambiamenti effettuati.
Grazie all’uso di un VCS è possibile ripristinare una versione precedente e questo rende più sicuro editare il contenuto di un file perché possiamo sempre ripristinare una precedente versione. Inoltre, un sistema di versionamento tiene traccia di chi ha effettuato una modifica e quando la modifica è stata effettuata.
Files che sono gestiti da un VCS sono salvati all’interno di quello che viene comunemente definito un repository.
Quando delle modifiche sono fatte a un file, l’utente del VCS può salvare (anche detto committare nel contesto dei
VCS) le modifiche all’interno del repository e di conseguenza creare quello che viene definito un punto di revisione
(revision point).
Durante la creazione di un punto di revisione, il sistema di versionamento crea uno snapshot (immagine) di tutte le modifiche fatte.
Uno dei sistemi di versionamento più utilizzati al momento è Git, creato da Linus Torvalds (il creatore di Linux) nel 2005.
Inizialmente Torvalds creò Git per dei problemi nati con gli altri VCSs esistenti e il suo utilizzo era inteso per
chi stava lavorando sul codice del kernel di Linux ma divenne molto famoso in tempi brevi e a oggi è sicuramente il
sistema di versionamento del codice più popolare al mondo!
Test unitari / Unit Testing
Testare il codice che scriviamo è assolutamente essenziale in quanto ci permette di verificare la correttezza del
nostro codice.
Un altro importantissimo motivo per scrivere tests è che ci permettono di verificare che le modifiche che abbiamo
effettuato non abbiamo introdotto alcun bug in parti del codice che precedentemente funzionavano correttamente e in
questo contesto, gli unit tests funzionano come test di regressione controllando che tutto quello che
precedentemente funzionava, continui a funzionare correttamente.
Innanzitutto chiariamo che possiamo avere diversi tipi di tests e gli unit tests sono solo un tipo anche se un tipo molto importante.
Il termine unitari (unit) deriva dal fatto che questo tipo di test verificano un unità di codice che spesso è una funzione ma in generale possiamo dire una piccola unità di codice.
Solitamente è il programmatore che ha scritto la suddetta unità di codice a scrivere anche gli unit tests per il
codice e spesso vengono eseguiti in maniera automatizzata nel senso che, quando abbiamo finito di scrivere il codice
e creato i tests, il sistema di versione del codice dovrebbe lanciare in automatico i tests e verificarne la
correttezza.
Nel caso che anche un solo test fallisse, dovrebbe prevenire la possibilità di salvare il codice nel repository per
evitare che ci sia del codice con test che falliscono e quindi, probabilmente, con bugs o comportamenti inaspettati.
Tests d’integrazione / Integration Tests
Tests d’integrazione si occupano di mettere il relazione diverse unità di codice che lavorano insieme in collaborazione.
Unità che lavorano insieme hanno bisogno di comunicare e comunicheranno scambiandosi informazioni. Quindi i tests d’integrazione si occupano di controllare i dati trasferiti e la loro rappresentazione, fra unità di codice separati, e che ciò funzioni per come ci aspettiamo.
Tests di accettazione / Acceptance Tests
Di solito gli acceptance tests sono divisi in quattro sotto categorie:
- User acceptance testing
- Operation acceptance testing
- Constructional and regulatory acceptance testing
- Alpha and beta testing
User acceptance testing
Lo scopo di questa categoria di tests è quello di verificare che il programma funzioni per come aspettato
nell’ottica dell’utente finale.
Attraverso l’utilizzo di acceptance tests cerchiamo di rispondere ad alcune domande come per esempio, può l’utente
finale utilizzare in software, il software rispecchia quello che l’utente ha chiesto, ci sono problemi nel suo
utilizzo o ancora, l’applicazione si comporta per come era stato definito.
Operation acceptance testing
Questo viene ottenuto testando l’operatività dell’applicazione prima che il software venga rilasciato agli utenti finali. In pratica dobbiamo verificare che tutte le operazioni che il software deve avere, siano presenti e funzionino correttamente.
Constructional and regulatory acceptance testing
In questa tipologia di tests dobbiamo verificare che il software sviluppato rispecchi le condizioni specificate
negli accordi con il cliente che ha richiesto lo sviluppo del software.
Un altro aspetto riguarda tests che devono verificare che il software rispetti specifiche normative, per esempio
applicazioni in ambito finanziario devono rispettare diverse normative legislative.
Alpha and beta testing
Ci sono altri due tipi di tests che sono effettuati per verificare e identificare tutti i possibili problemi e bugs.
Alpha testing viene effettuato nelle fasi iniziali dello sviluppo mentre beta testing è fatto nella fase
finale dello sviluppo.
Entrambi sono condotti dai potenziali utenti dell’applicativo o da un gruppo di persone con competenze simili a quelle degli utenti finali.
Tests di regressione / Regression tests
I tests di regressione vengono effettuati per scovare dei problemi dopo un cambio di codice significativo, il quale può aver impattato anche funzionalità che precedentemente funzionavano correttamente.
Praticamente un bug di regressione è un errore che provocherà lo stop dell’applicazione o un malfunzionamento in essa a seguito di un aggiornamento. Un ulteriore variante è quella legata a un degrado delle performance dell’applicazione a seguito di un aggiornamento.
Rilasci del software
Quando iniziamo a lavorare allo sviluppo di un software, lo facciamo perché vogliamo creare un prodotto da poter rilasciare all’utente finale ma non vogliamo iniziare a lavorare al progetto includendo tutto quello che l’applicazione deve fornire e dopo mesi o anni, pubblicare il prodotto finito.
Il motivo per il quale non vogliamo fare ciò è che con il passare del tempo, molte cose possono cambiare come i requisiti funzionali, le regolamentazioni che il software deve rispettare o anche un prodotto di un concorrente può essere stato rilasciato sul mercato nel frattempo che potrebbe far cambiare la direzione inizialmente presa dal cliente.
Quello che invece vogliamo fare è d’iniziare a lavorare sulle delle funzionalità centrali, rilasciare una versione
che comprenda tali funzionalità all’utente e immediatamente dopo, iniziare a lavorare su una successiva iterazione
che conterrà ulteriori funzionalità.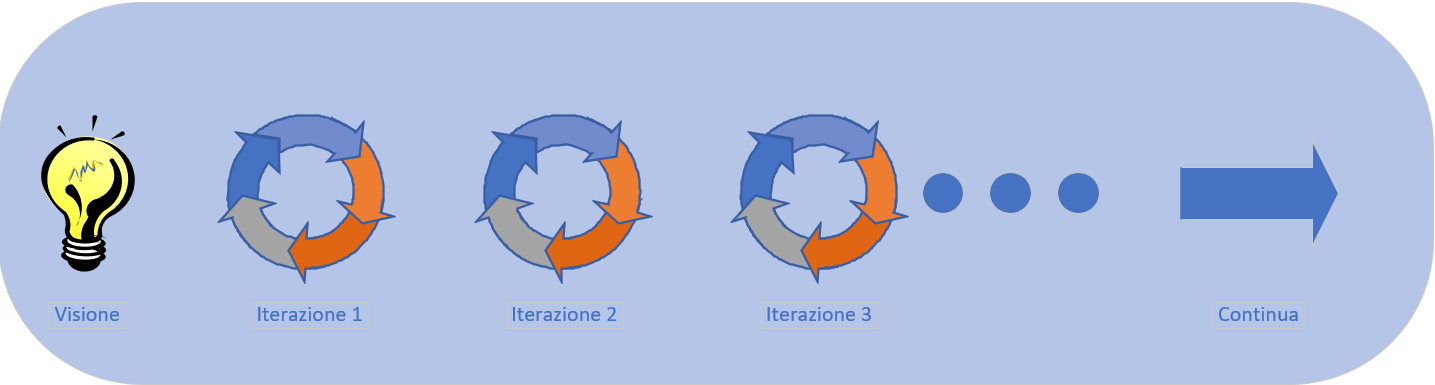
Processo di sviluppo attraverso iterazioni continue
Come vediamo dal grafico, iniziamo da un idea. Successivamente sviluppiamo alcune delle parti fondamentali dell’idea e questa parte viene definita un iterazione. Alla fine di un iterazione avremo del codice funzionante che possiamo rilasciare all’utente finale.
Il prossimo step è quello d’iniziare una nuova iterazione, implementare ulteriori funzionalità che verranno rilasciate al cliente finale alla fine dell’iterazione e questo processo continuerà nuovamente.
I passi da eseguire durante ogni iterazione possono variare e dipendono dalla metodologia di sviluppo che adottiamo
ma il processo, in generale, rispecchia il seguente grafico:
Il processo con il quale rendiamo disponibile all’utente il software sviluppato viene chiamato Rilascio e Deployment.
Una volta terminata la singola iterazione, passiamo alla successiva. Un altro vantaggio di un processo iterativo è quello di avere la possibilità di rifinire il nostro processo, iterazione dopo iterazione.
Per esempio, possiamo applicare delle metriche durante ogni iterazione per fare una stima di quanto lavoro riusciamo
a fare, identificare modi per migliorare il processo attraverso una valutazione di cose che non sono andate per come
ci aspettavamo durante l’iterazione precedente o cose che possono essere migliorate e possiamo definire quello che
andrà nella prossima iterazione in modo da ripetere l’intero processo.
Questo concetto sta alla base di quello che viene definito Continuous Improvement cioè un miglioramento
costante attraverso processo iterativi.
Rilascio del Software
Quando abbiamo del software che può essere rilasciato, dobbiamo deployarlo.
Deployment è il processo attraverso il quale ci assicuriamo che il software è stato installato nel posto corretto, che abbiamo preso tutte le precauzioni di sicurezza e che i privilegi sono stati settati correttamente in modo da avere le corrette autorizzazioni per la lettura e scrittura dei files necessari al nostro programma.
Solitamente, una volta che il software è stato deployato, vogliamo testarlo nuovamente per assicurarci che tutto funzioni correttamente.
Il processo di deploy, di norma, richiede diversi passaggi.
Gli sviluppatori avranno un server che è utilizzato durante lo sviluppo del software e viene chiamato server di
sviluppo o development server e durante lo sviluppo il codice può essere eseguito e testato su questo
server.
Inoltre, visto che la maggior parte degli applicativi userà qualche tipo di database per salvare i dati, avremo la
necessità di avere anche un database di sviluppo con dei dati di test usati dall’applicazione.
Il vantaggio di usare un infrastruttura specifica per la parte di sviluppo è quello di poter modificare i dati secondo le nostre esigenze senza impattare i dati reali che sono usati dall’applicazione.
Prima di deployare il software su un server di produzione, che è quello usato dagli utenti finali, di solito c’è uno step intermedio che è quello di fare il deploy su un altro server chiamato lo staging server.
Il ruolo dello staging server è quello di rispecchiare il più possibile il server di produzione in modo da
testare il nostro applicativo su un server che rispecchia quello di produzione con configurazioni, dipendenze e
settaggio uguali.
Lo staging server ha spesso associato un database con dati che sono un sottoinsieme di quelli presenti su produzione
in modo da testare, il più possibile, il software con dati che rispecchiano quelli reali.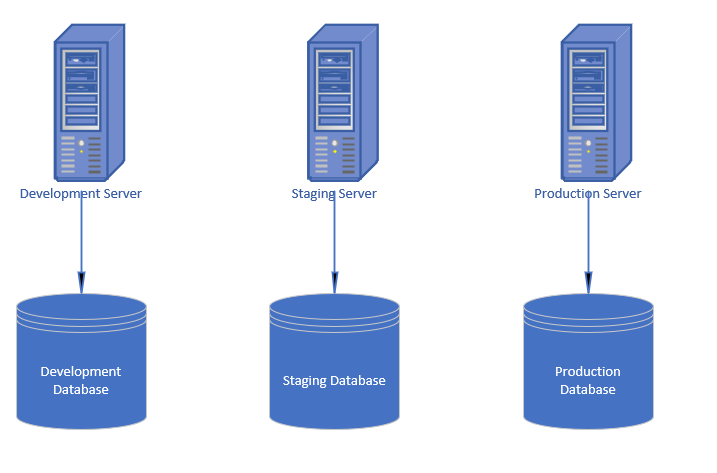
Alla fine di questo processo, se siamo soddisfatti con i risultati ottenuti, il software viene deployato sul server di produzione e può essere usato dagli utenti finali.
A parte lo spostare fisicamente il nostro software sul server di produzione, ci può essere l’esigenza di ulteriori steps come per esempio configurazioni che devono essere applicate al database di produzione o al server stesso, aggiungere dipendenze necessarie all’applicativo e così via.
Una delle leggi di Murphy dice:
Se c’è il 50% di probabilità che una cosa andrá male, 9 volte su 10 accadrà!
Magari è meglio non essere così disfattisti ma sicuramente dobbiamo prendere in considerazione che qualcosa può
andare male.
Quello che vogliamo è di avere una rete di sicurezza quando eseguiamo un deploy e questa viene chiamata una
strategia di rollback.
Dobbiamo avere un modo per ripristinare una versione precedente del software nel caso in cui il nuovo deploy causi
dei problemi alla nostra applicazione.
I passaggi per eseguire un deploy in produzione sono spesso automatizzati e questo vuol dire, utilizzare dei tools e delle applicazioni che si occupano di eseguire tutti i passaggi richiesti.
Deployment automatico
L’idea alla base di un deployment automatico è quella di automatizzare più steps possibili e il motivo dipende dal
fatto che spesso questi passaggi devono essere eseguiti nell’ordine corretto e quindi si prestano molto all’automazione.
Un altro motivo è dovuto al fatto che facendo questi passaggi manualmente è facile dimenticarsi di eseguire qualcosa
o eseguirli nell’ordine non corretto.
Di norma, un deployment automatico ci offre una sicurezza di qualità superiore sia per i motivi sopra elencati ma anche perché possiamo automatizzare l’esecuzione dei tests ed assicurare che soltanto quando tutti i tests passano correttamente il deploy viene effettuato.
Altro motivo molto importante per automatizzare il deploy riguarda la velocità, eseguire un deploy manualmente può essere molto dispendioso in termini di tempo e considerando la frequenza dei deploy, questo può comportare anche uno spreco economico notevole.
Manutenzione del codice
La verità che va subito detta è che un tipico sviluppatore passerà la maggior parte del suo tempo a mantenere codice esistente piuttosto che scrivere codice nuovo ed eccitante!
Tutti i programmi che sono utilizzati avranno sempre l’esigenza di essere mantenuti dato che gli utenti troveranno sempre bugs che devono essere fixati, nuove funzionalità che devono essere aggiunte quando gli utenti ne chiederanno di nuove e funzionalità esistenti avranno la necessità di essere aggiornate e migliorate.
Questo vuol dire che i programmatori passeranno la maggior parte del loro tempo su codice vecchio, codice che può essere stato scritto un decennio fa o soltanto qualche settimana fa.
Spesso, nell’immaginario collettivo, un programmatore produrrà codice che usa le ultime tecnologie presenti sul mercato e scriverà programmi super eccitanti ma la verità è tutt’altra ed è meglio che questo punto venga chiarito subito e onestamente.
Questa è la vita del programmatore!
Metodologie di Sviluppo del Software
Durante il tempo, sono state sviluppate e affinate diverse metodologie di sviluppo per aiutare il processo a essere più produttivo e creare software di qualità migliore.
Analizziamo brevemente le tipologie più conosciute, vantaggi e svantaggi per ognuna di esse.
Metodologia Waterfall
Questa metodologia, molto utilizzata in passato, ha evidenziato enormi limitazioni in quanto non considera i continui cambi dei requisiti che si verificano quando sviluppiamo un software.
Il modello Waterfall definisce una serie di passi statici che devono essere eseguiti in una predeterminata sequenza.
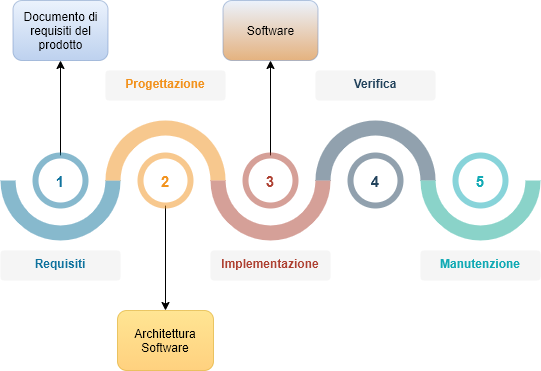
Vediamo come funzione questo modello:
- Come primo step, vengono definiti i requisiti che l’applicazione deve avere
- Viene fatta una progettazione del sistema in cui vengono descritte come responsabilità diverse saranno divise per costituire parti diverse del software
- Viene scritto il codice
- Il codice viene testato
- Il software viene rilasciato e si entra nella fase di manutenzione
La critica maggiore che viene sollevata alla metodologia Waterfall è che lo sviluppo è poco adattabile a eventuali
cambi che spesso si verificano.
Il processo si sviluppa a partire da un idea fino alla sua fase finale ma durante questo periodo, il software può
avere la necessità di adattarsi a cambi come per esempio, modifiche della legislazione che l’applicativo deve
rispettare, modifiche alle funzionalità, software concorrenti che ci forzano a rivedere le scelte fatte all’inizio e
così via.
Utilizzando una metodologia troppo rigida potremmo finire con lo sviluppo di un software che è già vecchio prima ancora di rilasciarlo in produzione e di conseguenza è la nata la necessità di adottare altre metodologie di sviluppo più flessibili.
Lo sviluppo Agile
La branca dello sviluppo software agile fa riferimento ad un gruppo di metodologie, tutte basate su uno sviluppo iterativo.
Link: Manifesto Agile — Principi del manifesto Agile
Vediamo alcune fra le metodologie più popolari.
Metodologia Agile Scrum
Questa metodologia, meglio conosciuta come Scrum, è un framework di gestione dei progetti “lightweight” che usa un approccio iterativo e incrementale.
In Scrum, il product owner, che è la persona con il potere di decidere quali task andranno nelle varie iterazioni, gioca un ruolo centrale e deve avere un ruolo attivo nell’intero processo di sviluppo.
Il product owner lavora a stretto contatto con il team di sviluppo per creare una lista di tasks prioritizzati delle funzionalità che devono essere implementate, chiamato il product backlog.
Il product backlog, praticamente, consiste di qualunque cosa abbiamo bisogno per consegnare un sistema software che funzioni.
Gli elementi nel backlog possono essere cose come, nuove funzionalità che devono essere implementate, bug fixes ma anche cose non strettamente funzionali come verifica dell’integrità dei dati, accessibilità e altro.
Quando, ai tasks nel backlog sono state assegnate delle priorità, il team di sviluppo (e potenzialmente altri ruoli che devono essere coinvolti) inizierà lo sviluppo di quello che viene definito, un potenziale “shippable increments”.
Quello che questo vuol dire è che, verranno presi dal backlog alcuni dei task con priorità più alta e si inizierà l’implementazione durante un breve periodo di tempo, definito come uno sprint.
Uno sprint, tipicamente, dura fra i 14 e i 30 giorni.
Il risultato di uno sprint dovrebbe, preferibilmente, dare vita a qualcosa di completamente funzionale in modo da poter essere rilasciato agli utenti per essere utilizzato. A questo punto, il team, inizierà un nuovo sprint e questo processo verrà ripetuto tutte le volte che è necessario.
Sviluppo Software Lean
Anche questa, come Scrum, è una metodologia iterativa e il suo focus è quello di deliverare porzioni di rilascio completamenti funzionanti. Lean è una metodologia molto flessibile e non impone alcuna particolare regola.
L’idea principale è quella di eliminare quello che viene chiamato waste. Questo viene ottenuto lasciando gli utenti scegliere le funzionalità da rilasciare nel sistema.
Il flusso principale di feedback arriva direttamente dagli utenti del sistema e i tasks su cui lavorare sono presi direttamente dall’ input degli utenti.
Extreme Programming (XP)
Questa metodologia è stata inizialmente teorizzata da Kent Beck, il quale ha portato le buone pratiche di programmazione a un livello estremo come per esempio l’introduzione formale delle code reviews.
Una pratica standard è quella che un altro sviluppatore dovrebbe rivedere tutto il codice prima che questo venga mergiato con il codice che costituirà la prossima release del software. In XP, questo viene fatto attraverso il concetto di pair programming.
Pair programming è quando due sviluppatori usano un solo computer per sviluppare il codice.
Uno sviluppatore è il guidatore (in inglese il driver) che sarà quello che scrive il codice.
L’altro sviluppatore, chiamato l’osservatore (in inglese l’observer) che rivede il codice che il
guidatore sta scrivendo. I due si scambieranno i ruoli con una certa frequenza.
Rispetto alla classica code review, dopo il codice viene esaminato in una fase successiva rispetto alla scrittura del codice, il pair programming ha il vantaggio di velocizzare il processo visto che la review viene fatta durante la fase di sviluppo.
Un ulteriore vantaggio è dato dal fatto che il guidatore potrà sempre ricevere immediatamente dei feedbacks dall’osservatore su come risolvere un dato problema.